
Migrating Azure Functions from v1 (.NET) to v2 (.NET Standard)
Lessons learned moving my link shortener app to the new platform.
On September 18th, 2017 I committed the first version of my serverless link shortener app to GitHub. The ⚡ serverless app allows me to tag links with short URLs that I share in tweets, blog posts, presentations, and other media. A user clicks on the link and is redirected to the target site, then I collect rudimentary data such as the referring URL (if it’s available) and the user agent information to parse the browser and platform being used. This feeds into an Azure Cosmos DB database that I analyze with Power BI to determine what topics and links are popular (or not). I also have a Logic App that runs to parse additional metadata from Twitter-sourced referrals.
The overall architecture looks like this, using serverless functions, table storage, queues, a NoSQL database and cloud-based integrations to Twitter:
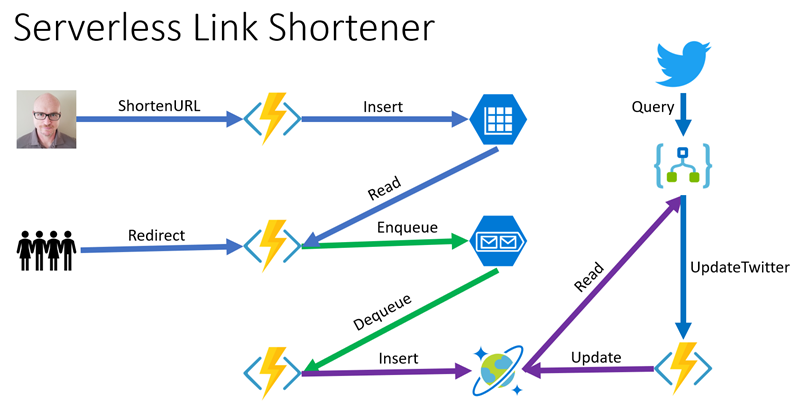
Link Shortener Application
I wrote extensively about the process and published all of the code to GitHub, so you can follow the links in the previous paragraph if you want to learn more of the background story. At the time I built the Azure Functions portions of the app, the production version was v1 and used the .NET Framework. As of this writing, the production version is v2 and uses .NET Core and .NET Standard libraries. To take advantage of all the updates rolling into the latest version and keep current, I chose to migrate my functions to the latest version.
Background
The original functions engine hosted .NET applications. Due to numerous reasons, including compatibility and performance, the second version hosts .NET Core applications (the functions app is essentially a .NET Standard 2.0 class but implemented as .NET Core app). To keep current and take advantage of the latest updates, I decided to migrate my application to .NET Core. The path I chose to follow was:
- Create a .NET Core Azure Functions v2 project
- Migrate existing business classes over
- Recreate all the function endpoints in the new project
- Test locally
- Deploy to the existing function app host and overwrite the legacy version
I knew I wasn’t risking much with the migration, because I could roll back to the previous version at any time.
Migrating Business Logic
The classes used to hold data all migrated 100% “as is.” I could have changed the class library to a .NET Standard library, but for the sake of expediency I simply pulled the class library into the new project under the Domain namespace. Code like the AnalyticsEntry designed to capture metadata migrated without changes.
public class AnalyticsEntry
{
public string ShortUrl { get; set; }
public Uri LongUrl { get; set; }
public DateTime TimeStamp { get; set; }
public Uri Referrer { get; set; }
public string Agent { get; set; }
}Even classes with business logic didn’t require any code changes. Part of this is because I am a firm believer in the strategy pattern. Instead of parsing URL fragments directly with a class that is specific to the framework, the strategy is defined as an action that takes a URL and returns a name/value collection of its parts. This code was the same in v1 and v2:
public static string AsPage(this Uri uri, Func<string, NameValueCollection> parseQuery)
{
var pageUrl = new UriBuilder(uri)
{
Port = -1
};
var parameters = parseQuery(pageUrl.Query);
foreach (var check in new[] {
Utility.UTM_CAMPAIGN,
Utility.UTM_MEDIUM,
Utility.UTM_SOURCE,
Utility.WTMCID })
{
if (parameters[check] != null)
{
parameters.Remove(check);
}
}
pageUrl.Query = parameters.ToString();
return $"{pageUrl.Host}{pageUrl.Path}{pageUrl.Query}{pageUrl.Fragment}";
}The call to the extension method is also the same:
var page = parsed.LongUrl.AsPage(HttpUtility.ParseQueryString);
If the ParseQueryString method ever went away from the framework, the strategy pattern would allow me to implement the same functionality in my own method and pass that instead. For security, I built in a check to ensure the function is running under HTTPS. The check looked like this in v1:
private static HttpResponseMessage SecurityCheck(HttpRequestMessage req)
{
return req.IsLocal() || req.RequestUri.Scheme == "https" ? null :
req.CreateResponse(HttpStatusCode.Forbidden);
}In .NET Core, the extension method isLocal does not exist. The goal is to allow HTTP only when running/debugging locally. This was a simple fix: in the existing static Utility class, I simply added this extension method to keep the security check “as is”:
public static bool IsLocal(this HttpRequestMessage request)
{
return request.RequestUri.IsLoopback;
}Another important but subtle change is logging. In v1 the original strategy was to pass in a TraceWriter instance to the function. The built-in dependency injection engine in the functions host would pass an appropriate instance, and logging looked like this:
log.Info($"Attempting to retrieve file at path {filePath}.&");
In v2, an interface is used instead. This gives more flexibility to swap a different implementation, both at run-time and for testing. The parameter becomes an ILogger instance and logging looks like this:
log.LogInformation($"Attempting to retrieve file at path {filePath}.");
There were only two other areas of the application that had to change. The first was a utility used to parse the user agent string to extract data about the browser. This class doesn’t exist in .NET Core and it forced me to pull in a third-party open source library that does a better job. I’ll discuss that more in a bit. The second change was required for the bindings to connect with storage and Cosmos DB.
HTTP Responses
In v1 it was possible to use some helper methods to create appropriate response codes. For example, when a request came in for ROBOTS.TXT, the code to return the result looked like this:
var robotResponse = req.CreateResponse(HttpStatusCode.OK, Utility.ROBOT_RESPONSE, "text/plain");
return robotResponse;This throws an exception in some circumstances in v2 due to internal nuances around how the extension method is implemented and the scope of the response (as far as I can understand, the response goes out of scope before the content is serialized). The solution when/if the error does occur is to explicitly create the response. I changed the code to this:
var resp = new HttpResponseMessage(HttpStatusCode.OK);
resp.Content = new StringContent(Utility.ROBOT_RESPONSE,
System.Text.Encoding.UTF8,
"text/plain");
return resp;…and that works fine.
Adding Extensions
By default, v1 provided access to many existing triggers (to execute the functions code) and bindings (to make it easier to connect to resources). In v2, the philosophy is to start with the bare minimum and add only what’s needed. The short links are stored in table storage as key/value pairs, and the only requirement to make the same code work in v2 was to add a package reference to:
Microsoft.Azure.WebJobs.Extensions.Storage
A binding is used to insert analytics data into a Cosmos DB database. In v1, the API used and therefore the binding was named DocumentDB. For v2, I simply renamed it to CosmosDB and added this reference:
Microsoft.Azure.WebJobs.Extensions.CosmosDB
I also track some custom telemetry with application insights, so I brought in the .NET Core version of the package. All of the APIs are the same so none of my code had to change.
Migrating Proxies
Proxies are another great feature of Azure Functions. They provide the ability to modify incoming requests and responses and route public APIs to internal endpoints that may be different. In v1, my proxies definition looked like this:
{
"$schema": "http://json.schemastore.org/proxies",
"proxies": {
"Domain Redirect": {
"matchCondition": {
"route": "/{shortUrl}"
},
"backendUri": "http://%WEBSITE_HOSTNAME%/api/UrlRedirect/{shortUrl}"
},
"Root": {
"matchCondition": {
"route": "/"
},
"responseOverrides": {
"response.statusCode": "301",
"response.statusReason": "Moved Permanently",
"response.headers.location": "https://blog.jeremylikness.com/?utm_source=jlikme&utm_medium=link&utm_campaign=url-shortener"
}
}
}
}The “Domain Redirect” route takes anything at the root and passes it to the full API. This essentially transforms a call to https://jlik.me/XYZ to http://jlikme.azurewebsites.net/api/UrlRedirect/XYZ. The “Root” route takes any “empty” calls (no short code) and redirects those to my blog.
The v2 engine fully supports proxies with an additional feature: you can define localhost to access any endpoints hosted in the same function app. For this reason, my “Domain Redirect” route changed to this:
"backendUri": "http://localhost/api/UrlRedirect/{shortUrl}"
Proxies are part of the functions engine so they are parsed and can be tested locally.
UA Parser
A large part of my motivation for creating my own link shortener was to have control over my own data. I look at dashboards weekly to determine what topics are popular (and which links have no interest) and to understand what platforms are being used. The main source of metadata for this is the “user agent” that is passed in the HTTP request header. A typical user agent looks something like this:
Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.16 Safari/537.36
Through arcane wizardry you can parse the user agent and extract information about the browser, platform, and whether the agent is an automated bot. In the above example, the browser is Chrome version 31 and the platform is Windows 7. In v1, I used a .NET class that helps parse browser capabilities. The logic looked like this:
var capabilities = new HttpBrowserCapabilities()
{
Capabilities = new Hashtable { { string.Empty, parsed.Agent } }
};
var factory = new BrowserCapabilitiesFactory();
factory.ConfigureBrowserCapabilities(new NameValueCollection(), capabilities);
factory.ConfigureCustomCapabilities(new NameValueCollection(), capabilities);
if (!string.IsNullOrEmpty(capabilities.Browser))
{
var browser = capabilities.Browser;
var version = capabilities.MajorVersion;
var browserVersion = $"{browser} {capabilities.MajorVersion}";
doc.browser = browser;
doc.browserVersion = version;
doc.browserWithVersion = browserVersion;
}
if (capabilities.Crawler)
{
doc.crawler = 1;
}
if (capabilities.IsMobileDevice)
{
doc.mobile = 1;
var manufacturer = capabilities.MobileDeviceManufacturer;
var model = capabilities.MobileDeviceModel;
doc.mobileManufacturer = manufacturer;
doc.mobileModel = model;
doc.mobileDevice = $"{manufacturer} {model}";
}
else
{
doc.desktop = 1;
}
if (!string.IsNullOrWhiteSpace(capabilities.Platform))
{
doc.platform = capabilities.Platform;
}The functionality was very limited. Here’s a snapshot of stats gathered with the old method:
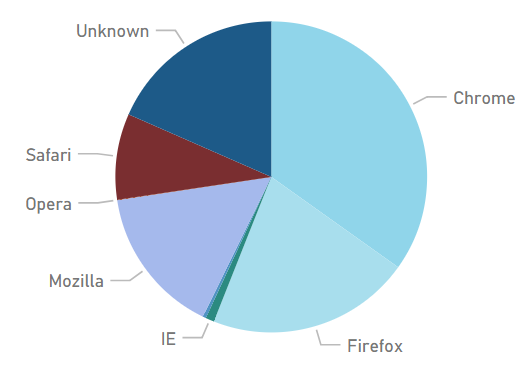
v1 Browser Data
The “browser capabilities” functionality doesn’t exist out of the box in .NET Core, so I did some research and landed on the UA Parser project. It contains some advanced logic to generically parse user agent strings and can be augmented with a set of configuration files that contain metadata about known agents. I have no desire to keep up with the latest files, so I chose to go with the basic metadata. This is a great aspect of Azure Functions: the ability to integrate third-party packages. The logic changed to this:
var parser = UAParser.Parser.GetDefault();
var client = parser.Parse(parsed.Agent);
{
var browser = client.UserAgent.Family;
var version = client.UserAgent.Major;
var browserVersion = $"{browser} {version}";
doc.browser = browser;
doc.browserVersion = version;
doc.browserWithVersion = browserVersion;
}
if (client.Device.IsSpider)
{
doc.crawler = 1;
}
if (parsed.Agent.ToLowerInvariant().Contains("mobile"))
{
doc.mobile = 1;
var manufacturer = client.Device.Brand;
doc.mobileManufacturer = manufacturer;
var model = client.Device.Model;
doc.mobileModel = model;
doc.mobileDevice = $"{manufacturer} {model}";
}
else
{
doc.desktop = 1;
}
if (!string.IsNullOrWhiteSpace(client.OS.Family))
{
doc.platform = client.OS.Family;
doc.platformVersion = client.OS.Major;
doc.platformWithVersion = $"{client.OS.Family} {client.OS.Major}";
}The data is richer, as this snapshot shows:
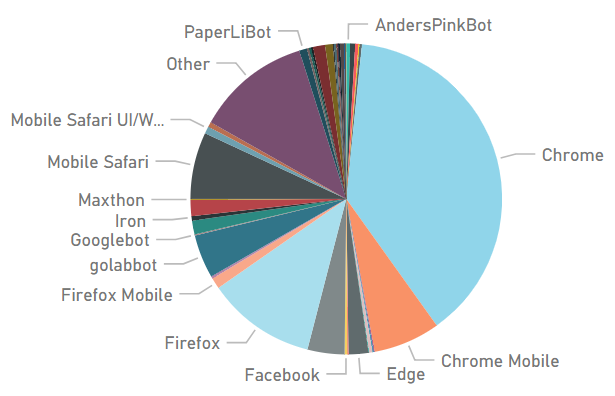
I am still figuring out what information I can collect and how to instrument it, but it’s nice to have the extra fidelity and have options to increase granularity.
Testing
Many people focus on the “serverless” aspect of Azure Functions, without recognizing it is a cross-platform engine that can run on Windows, Linux, or macOS machines and even execute from within containers. This makes it incredibly easy to test. I was able to test all endpoints using the Azure Storage Emulator. I could have installed an emulator for Cosmos DB as well, but it was just as easy to create a test instance of the database and update my local connection string to test the analytics metadata. I was even able to test proxies locally prior to deploying.
Deploying
“Friends don’t let friends right-click deploy.”
I have a confession to make: I have not yet built a CI/CD pipeline for my functions app. Fortunately, both Visual Studio and Visual Studio Code are smart enough to do everything necessary to deploy the updated code. I did right-click and deploy to my existing functions endpoint. All my configuration for custom domains, connection strings, etc. remained the same. The deployment process automatically detected a different version of the runtime and updated the configuration appropriately. Within seconds I had a production deployment of the updated link shortener and was able to start using it immediately.
Summary
I have a bucket list of “next steps” I’d like to take with the project. I want to set up CI/CD. I want to create a deployment script to make it easier for anyone to create their own link shortener. I also wanted to migrate to the latest version and am happy not only for checking it off my list, but also for how easy it was. All told, the migration took me a few hours and has been running flawlessly for over a month now. As for performance compared to v1, it appears to be about the same.
The following snapshot is from an hour of activity. The “failed” indicator you see is not a failure in the service, but a failed look up meaning someone passed an invalid code.
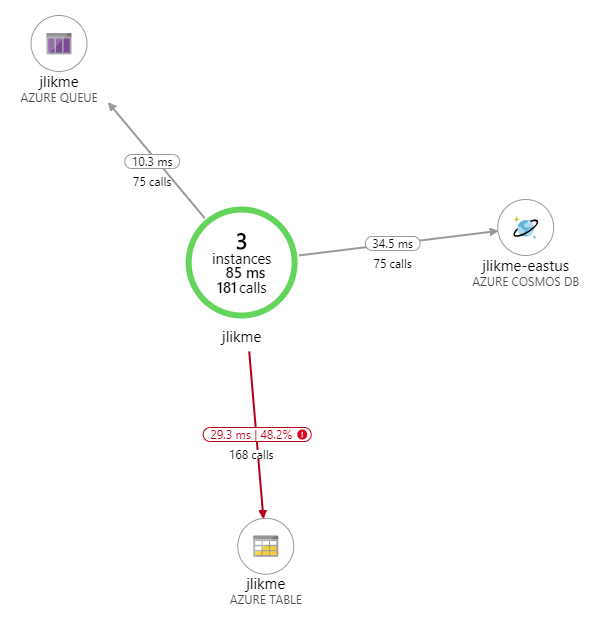
As you can see, performance is great across the board. Do you have a v1 functions app you are considering migrating? Have you already gone through the process? I would love to hear your thoughts and feedback in the comments below!
💡 For a complete list of considerations when migrating to v2, read the breaking changes notice
Regards,
Related articles:
- Azure Cosmos DB With EF Core on Blazor Server (Azure)
- Introduction to Azure Cloud Shell (Cloud Computing)
- Lift and Shift your .NET App to Azure (Cloud Computing)
- Moving From Lambda ƛ to Azure Functions <⚡> (Azure Functions)
- Serverless HTTP With Durable Functions (Azure Functions)
- The Year of Angular on .NET Core, WebAssembly, and Blazor: 2019 in Review (Azure)