
Getting Behind the 9-Ball: Cosmos DB Consistency Levels Explained
Understand with examples what strong, bounded staleness, session, consistent prefix and eventual consistency levels mean
I’m not a huge sports fan, but I love my 9-ball. Between a short-lived college try and my first programming job, I did a little bit of everything. Somehow, I managed to go from working in a bookstore, a retail outlet, a fast food restaurant and selling electronics out of the trunk of my car to working in a pool hall full time for a year. I never lost my passion for the game and always feel the most relaxed when I’m watching or playing pool.

Pool tournaments usually involve a “race to something.” For example, a “race to 7” means the first person to win seven games wins that round. In a typical tournament and a large pool hall, you may have dozens of games running simultaneously. I read an excellent white paper that explains consistency levels using a baseball game analogy. Although it left me with a new understanding, I felt something was missing.
So, I applied what I learned to my passion for pool and came up with this.
In case you are not familiar with it, CosmosDB is a cloud-based NoSQL database service that supports several different APIs, allows you to replicate across global regions simply by clicking a button in the portal UI, and provides service-level agreements (SLAs) for availability, latency, throughput, and consistency. You can choose a default consistency level for the database and further override it on a per application or connection basis.
Consistency levels provide a trade-off between performance, availability, staleness, and ordering of your data. The easiest way I can think of to explain what this means is to walk through consistency levels through the lens of a pool tournament.
Wait, Who Cares?
Why do consistency levels even matter? In some cases, a local, single instance of a database may be perfectly fine. Most enterprise applications, however, demand fast turnaround (low latency) and resiliency (high availability). Low latency and high availability can be addressed with a distributed system, or multiple database nodes or clusters spread over a geographic area.
- If one node in a cluster goes down, the other nodes can step in to maintain availability
- If one cluster in a region goes down, the other regions can step in to maintain availability
- Having nodes in different regions brings the database closer to users in that region, which in turn provides lower latency and faster speeds
It would be nice if it were as simple as flipping a switch and having a distributed system. Unfortunately, distributed systems are complicated. The CAP theorem describes three guarantees:
- Consistency—every read is current with the latest writes
- Availability — every request (such as a read) gets a response
- Partition tolerance — if messages are lost or delayed, the system will still operate as a whole
The theorem states that it is only possible to provide two out of three of those guarantees at once. It’s impossible to provide all three. Network failures and delays are a normal reality, so that puts the spotlight on consistency and availability. CosmosDB provides a high availability guarantee and provides the ability to “dial in” a consistency level to trade-off with performance.
Bonus: if you want to dig even deeper, take a look at the PACELC theorem.
The Setup
To keep things simple, assume there are 20 players each matched up across 10 tables in a race to three. Designate them “A” and “B” at each table. To further simplify the model, assume every match ends up going back and forth with “A” ultimately winning. The score history at every table eventually looks like this:
- A — 1, B — 0
- A — 1, B — 1
- A — 2, B — 1
- A — 2, B — 2
- A — 3, B — 2 (A is the winner)
A score keeper is tracking the score at each table, and a large audience watching the tournament. Now I’ll walk you through each consistency level with this setup in mind.
Strong Consistency
Linearizability. Reads are guaranteed to return the most recent version of an item.

Strong consistency is probably the easiest to understand and what most traditional relational database management system (RDBMS, i.e. SQL or MySQL) developers tend to rely on. Essentially, anyone, anywhere, agrees on what is happening at any given point in time.
In our pool tournament, this creates a bit of overhead. Anytime the score changes at a table, that scorekeeper blows a whistle to stop everything while the score is shared. They update their score, then travel to every other table to inform the other scorekeepers. Finally, they go to the audience and make certain every audience member knows the score. Then they blow their whistle again and things resume. You can imagine this slows things down a bit.
To summarize, this model has:
- Highest consistency — everyone agrees
- Lowest performance — we need to make sure everyone is aware of every update before we continue
- Lowest availability — there is no real opportunity to scale out because adding new observers only increases the overhead
It is possible to maintain strong consistency in a distributed system through quorum. When multiple copies of a document are maintained across multiple systems, changes are “voted on” and only committed when multiple nodes agree that change is acceptable (similarly, a number of votes must exist for an operation to abort). This sacrifices latency (you must wait for the votes to come in) and throughput (again, due to data having to pass across nodes). In our example, this is the action of the scorekeeper confirming with every other scorekeeper and audience member.
Because of the overhead inherently built into maintaining quorum, strong consistency costs almost twice as much as session, consistent prefix, or eventual consistency.
Data consistency: Highest
App availability: Lowest
Latency: High (bad)
Throughput: Lowest
Examples: Financial, inventory, scheduling
Bounded Staleness
Consistent Prefix. Reads lag behind writes by k prefixes or t interval.

Bounded staleness is a compromise that trades delays for strong consistency. Instead of guaranteeing that all observers have the same data at the same time, this level allows a lag to be specified in operations and/or time. For example, this database is configured to be at most 100 operations behind or five seconds delayed.
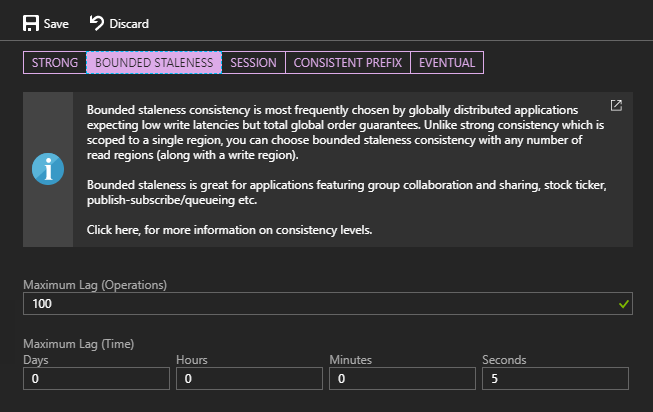
What does that mean, exactly?
In the case of our tournament, the scorekeeper doesn’t blow a whistle and stop the play. Instead, play continues, and the scores are logged with a timestamp. A centralized system collates these and broadcasts them on a scoreboard that everyone can read. Because it takes time to bring in the scores from the various tables, the scoreboard isn’t real-time. A player might win their tournament but must wait a few moments for the win to appear on the scoreboard.
The compromise here is that everyone is given a little breathing room to collate scores. In the case of CosmosDB, this means you can choose multiple regions because the lag gives time for data to replicate across those regions (as you may surmise, there are limits and specifying an operational lag of “one” is not allowed because that’s almost the same as strong consistency).
To summarize:
- Consistent beyond a user-defined threshold
- Provides a guarantee for “how eventual” eventual is
- This provides better performance than strong consistency
- It still is lower availability because of the inherent lag to synchronize all regions
- Like strong consistency, this is about twice as expensive as session, consistent prefix, and eventual consistency
Data consistency: High
App availability: Low
Latency: High
Throughput: Low
Examples: Apps showing status, tracking, scores, tickers, etc.
Session
Consistent Prefix. Monotonic reads, monotonic writes, read-your-writes, write-follows-reads.

Session consistency is the default consistency level for newly created databases and collections, and for good reasons. It is less than half as expensive as strong consistency and bounded staleness and provides both good performance and availability. Think of a session as your application or connection.
A good case for session consistency is the scorekeepers at each table. With bounded staleness, the scorekeeper could end up in this awkward situation:
- Writes A — 1 (B is still 0)
- Writes B — 1
- Reads the scorecard to validate
- Read returns A — 1, B — 0
Yes, in the world of NoSQL your reads don’t have to correlate with your writes, unless you use something like strong consistency. In this example, the bounded staleness did not guarantee up-to-date consistency because of the built-in delay, so the read returned the state from a previous point in time. Eventually, if they keep checking their scorecard, the score will end up at A — 1, B — 1.
Session consistency fixes this. It ensures whatever is written will be current for reads from that session. Anything else will be accurate but delayed. So, here’s what happens:
- Writes A — 1 (B is still 0)
- Writes B — 1
- Reads the scorecard to validate
- Read returns A — 1, B — 1 (guaranteed)
If the scorekeeper decides to kill time by looking at the score from other tables, they will see an accurate score but not necessarily a current one. In other words, Table 2 might currently be at A — 1, B — 1 but the scorekeeper sees A — 1, B — 0. Similarly, the audience always has an accurate score that may be delayed. A few seconds after the scorekeeper writes B — 1 the audience may still see B — 0. Eventually, the score catches up.
To summarize:
- Strong consistency for the session — all reads are current with writes from that session, but writes from other sessions may lag
- Data from other sessions comes in the correct order, just isn’t guaranteed to be current
- This provides good performance and good availability at half the cost of strong consistency and bounded staleness
If you want to move beyond the pool metaphor, think of a nutrition program with social sharing. The user who is inputting their meals should always see a current, accurate representation of calories and nutrient breakdowns for that day. However, other users in their social network don’t need to see those updates in real-time. They can eventually receive updates and tap a “like” button for a well-done healthy meal even if it appears after a short delay.
Data consistency: Moderate
App availability: High
Latency: Moderate
Throughput: Moderate
Examples: Social apps, fitness apps, shopping cart
Consistent Prefix
Updates returned are some prefix of all the updates, with no gaps.

This is one of the easiest consistency levels to explain if you understand the previous levels. I like to think of consistent prefix as bounded staleness without the operation lag/delay guarantees. Any observation is going to be accurate for a point in time but won’t necessarily be current.
In our pool tournament, the scorekeepers diligently keep score and update their scorecards. These are collated and broadcast on a scoreboard. With bounded staleness, the audience knows the scoreboard is always only a few scores or maybe a few minutes delayed. Using consistent prefix, that’s not so clear. When a lot of matches end at the same time, it may take longer for the scores to aggregate and update. As matches are being played and no scores are changed, the tally “catches up” and becomes current.
Ideally, scorekeepers have a special app that uses session consistency. The scoreboard and the pool stats app used by the audience both use consistent prefix.
To summarize:
- Reads are consistent to a specific point in time — i.e. scores are always accurate, just not necessarily current
- No guarantees on how current but in many cases, delays are likely to be in seconds and not minutes
- Good performance and excellent availability because the various nodes can take whatever time is needed to synchronize and agree on the current model
Data consistency: Low
App availability: High
Latency: Low
Throughput: Moderate
Examples: Social media (comments, likes), apps with updates like scores
Eventual Consistency
Out of order reads.

For the audience and scorekeepers at the pool tournament, eventual consistency would be a disaster. Eventual consistency is easy to understand: eventually, reads are consistent. There is no guarantee of how long that will take (like consistent prefix), but the other caveat is that updates aren’t guaranteed to come in order.
Consider this scenario:
- Scorekeeper enters A — 1 (now the score is A — 1, B — 0)
- Scorekeeper enters B — 1 (now the score is A — 1, B — 1)
- Scorekeeper enters A — 2 (now the score is A — 2, B — 1)
- Scorekeeper reads the score and sees A — 0, B — 1
- Audience looks at the scoreboard and sees A — 2, B — 0
In this case, the out of order updates means the scores may not represent reality. The “A” writes might come before the “B” writes even if the timing was different. Eventually, the score will end up at A — 2, B — 1 but there is no guarantee when and no way to really check that, yes, this is the current score.
So why would you even consider this consistency level?
First, because CosmosDB doesn’t have to guarantee point-in-time accuracy or even the order of writes, this is the highest performing, lowest cost, and highest availability model.
Second, there are some valid scenarios when this level is fine. For example, the pool league’s automated newsletter can probably get away with eventual consistency because when it polls the database hours after the tournament ends, there is a strong likelihood that consistency has, eventually, been reached.
Data consistency: Lowest
App availability: High
Latency: Low
Throughput: Highest
Examples: Non-ordered updates like reviews and ratings, aggregated status
Did this analogy work to help you better understand consistency levels? Leave your thoughts and feedback in the comments. You can also read the official documentation for CosmosDB consistency levels.
Regards,
Related articles:
- Azure Event Grid: The Whole Story (Cloud)
- Introduction to Cloud Storage for Developers (Cloud)
- Managing Data 📈 in the Cloud ☁ (NoSQL)
- Moving From Lambda ƛ to Azure Functions <⚡> (Cloud)
- My New Role as Senior Program Manager for .NET Data (NoSQL)
- Play the Chaos Game to Understand WebAssembly Memory Management (Programming)